
When Simple Components Create Complex Nightmares: Unveiling the Hidden Complexity of Microservices

Your team just "finished" decomposing the monolith into 47 microservices. Each one is a masterpiece of simplicity—CRUD endpoints, pristine REST APIs, 200 lines of logic. Any junior developer can grok a service in 10 minutes. The architects are high-fiving. The DevOps are sobbing (you assume it’s joy).

Six months later:
Deploying a feature requires 17 Slack threads, 5 Zoom wars, and a spreadsheet.
That “simple” product update triggers an API cascade that would make Rube Goldberg be proud.
Tweaking one line in
OrderServicejust nuked the recommendation engine (wait what? let me check that … yeah, checks out ).
Here’s why you deserve a hard slap to bring you back to reality: You didn’t reduce complexity. You just moved it somewhere else.
Welcome to the conservation of complexity—the law nobody wants to admit exists.

The 10-Minute Biology Lesson That Ruins System Architecture Assumptions
In the 1990s, Stuart Kauffman at the Santa Fe Institute asked: Why does life thrive at the edge of chaos? His answer—NK networks—is about to shatter your assumptions about “simple” architectures.
The NK Model: Why Systems Are Doomed
N = Number of components in your system.
K = Number of dependencies each component relies on.
Total complexity = How these dependencies interact.
Kauffman’s insight: K never disappears. It just moves.
In biology, complexity shifts between internal (organs) and external (ecosystems). Evolution redistributes K to minimize damage.
Your theoretical microservices migration? It did the opposite.
The Knowledge: You Can’t Destroy K—Only Displace It
Let’s talk about your UserService:
200 lines of pristine, junior-friendly code.
Internal K=0. Any bootcamp grad could maintain it in their sleep.
But to do anything useful, it needs to:
AuthServicefor token validationPreferenceServicefor user settingsNotificationServiceto send emailsAuditServiceto log changesAnalyticsServiceto track behaviorProfileServicefor display infoPermissionServicefor access rights
Your component K=0. Your system K=15.
You optimized for what you can see (simple components) while ignoring what you can’t (system simplicity).
The Math of Complexity
Total K is constant for a given business domain.
You can have
Low component K + high system K (what most teams do).
High component K + low system K (what smart teams aim for).
You can’t have both.
This is the conservation of complexity. Splitting services didn’t eliminate complexity—it spread it like gravy across your system.
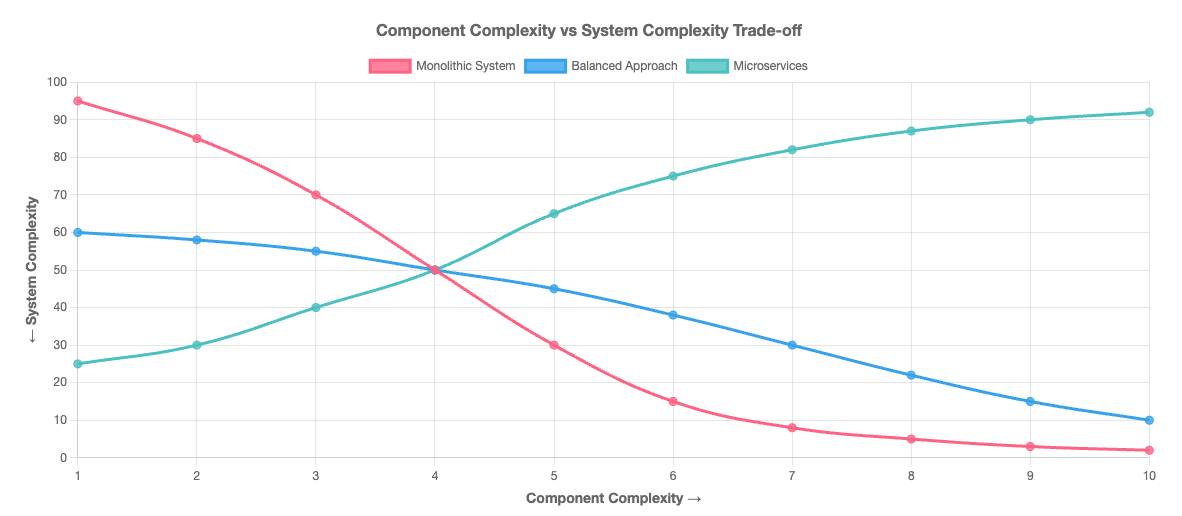
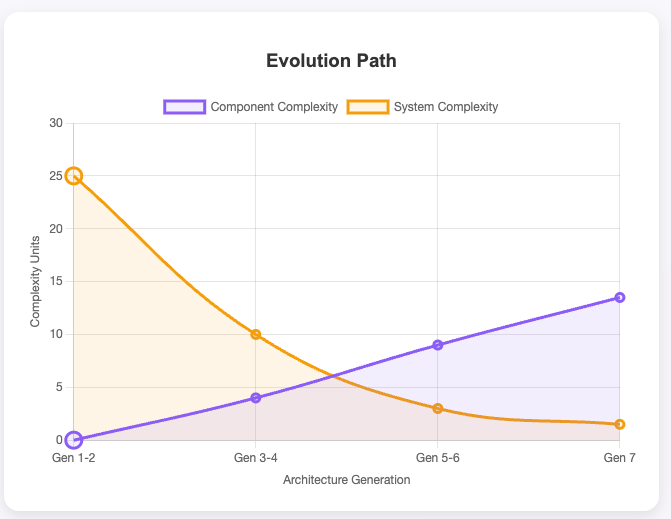
The Evolutionary Trade-off: Where Will Your Complexity Live?
The evolutionary architecture model isn’t about eliminating complexity. It’s about choosing where it lives—and where it hurts least.
Generation 1–2: Maximum System Pain
Component K: ~0 (trivially simple).
System K: 20–30 (everything talks to everything).
The cost: Junior devs are happy. Senior devs are drinking heavily. Every feature is a distributed systems nightmare.
Generation 5–6: The Complexity Containers
Component K: 8–10 (genuinely complex).
System K: 2–4 (minimal connections).
The payoff: New devs take weeks to onboard, but then ship without coordination.
This is where proper stratification becomes critical. Stratification doesn’t eliminate complexity—it manages it by isolating layers:
Domain layer: Complex business rules, contained and protected.
Infrastructure adapters: Integration complexity, explicit and bounded.
Generation 7: Maximum Component Pain
Component K: 12–15 (PhD-level complexity).
System K: 1–2 (near-zero coupling).
The reality: Your components are dissertations, but your system is a constellation, not a hairball.
* We didn’t touch this generation yet … you are not prepared ( still struggling to write a proper the post for it 😤 )
The Fractal Nature of K: It’s Complexity All the Way Down
K-values exist at every level of your system, forming a fractal pattern of complexity.
The same conservation law applies at every level. You can’t eliminate K—you can only choose which level absorbs it.
DDD Aggregate vs. “Simple” Microservice
The fractal view shows why some architectures feel manageable despite high complexity: They distribute K across levels instead of concentrating it in one place.
The Hidden Cost of "Simple" Services
When you split a system into smaller pieces, complexity doesn’t vanish—it just moves around. Think of it like this:
High system K (many dependencies between services): Complexity grows exponentially as you add more services. Example: 50 "simple" services × 30 dependencies each = a maintenance nightmare.
High component K (smart, self-contained components): Complexity grows linearly as you add more components. Example: 20 smart aggregates × 10 internal dependencies each = manageable and scalable.
Why this matters: 50 tiny services might seem simpler, but their interactions create chaos. 20 smarter components look more complex, but they isolate the chaos—making the system simpler.
The rule: Complexity is like energy—it can’t be destroyed, only moved or reshaped. (As I’ve written before in The Conservation of Complexity, what matters isn’t eliminating complexity—it’s choosing where it lives.)
🚨 ARCHITECT’S ALERT
The most dangerous architectural decision isn’t microservices vs. monoliths.
It’s believing you can eliminate complexity—when all you’re doing is moving it to where you can’t see it.
Every time someone says, “Let’s keep services simple,” they mean: “Let’s hide system complexity until it’s catastrophic.”
Every time someone says, “This component is too complex,” ask: “Where will that complexity go?” (Spoiler: Into the integration layer, where it’s 10x harder to debug.)
Most teams choose high system K because:
Component complexity is visible and easy to measure.
System complexity is invisible until it’s too late.
The Honest Path Forward
The evolutionary architecture model doesn’t eliminate complexity. It redistributes it. Here’s what it actually offers:
✅ Testable complexity (unit tests for components).
✅ Bounded complexity (failures stay local).
✅ Manageable complexity (teams control their domain).
✅ Linear scaling (not quadratic hell).
What it demands in return:
❌ No free lunches (some things get harder).
❌ No cheap hires (you need skilled devs).
❌ No magic bullets (trade-offs, not miracles).
The K-Value Decision Framework
When designing your systems, ask:
What’s our total K budget? (How much complexity does our domain require?)
Where should we spend it? (Components or connections?)
What are we optimizing for? (Hiring ease or shipping speed?)
What pain are we willing to accept? (Complex onboarding or complex coordination?)
There’s no “right” answer. But there are informed trade-offs and uninformed defaults.
I know I bashed microservices in this piece, but I did that only because they are way overused and abused, and a lot of teams are going, or went through the pain of wrongly chosen architecture and abstractions. They are a valid choioce, and they do have the their ups and can be very powerful in the proper context.

Most teams drift into high system K by accident—each “keep it simple” decision makes sense locally, but the global result is catastrophe.
Choose Your Complexity Wisely
Your architecture will have complexity. K is conserved, not eliminated.
The only question is: Where do you put it?
In components? Need seniors, but ship independently.
In the system? Hire anyone, but ship never.
The evolutionary model is just a map of trade-offs. Each generation shows a different way to distribute K. None are free. All are choices.
This connects to broader patterns I’ve explored:
Systems Archetypes (how relationships shape complexity).
Strategic DDD (bounded contexts as complexity containers).
The K-value framework makes it explicit: Complexity isn’t a bug. It’s a feature of your domain. The art is distributing it intentionally.
Next time someone says they’re making things “simpler,” ask them: “Simpler where?” Because complexity doesn’t disappear. It just moves to where you’re not looking