
Gen 5: DDD Aggregates - Encapsulating Business Logic in Domain Objects

As our e-commerce platform continues to mature, we notice a significant shift in how we think about our business domain. What began as simple data operations has evolved into a rich set of rules, behaviors, and relationships. Order processing now involves sophisticated validation, multi-step workflows, and complex state transitions. Product management encompasses intricate pricing strategies, inventory tracking, and categorization rules.
In our previous architectural generations, we addressed this growing complexity by separating concerns across different layers and components. But now, we face a more fundamental question: where should the core business logic actually live? Should it remain in service methods, scattered across command handlers, or should it move into the domain objects themselves?
This question brings us to the fifth generation in our architectural evolution: Domain-Driven Design (DDD) with Aggregates. This approach represents a profound shift in how we model our system—moving from a primarily procedural structure to a truly object-oriented domain model where behavior and data are encapsulated together in meaningful business objects.
In DDD, the domain model isn't just a data structure; it's a living representation of business concepts with both state and behavior. Aggregates serve as consistency boundaries, ensuring that related entities are modified together while protecting important business invariants. This approach aligns our code more closely with how business experts think about the domain, creating a ubiquitous language that bridges the gap between technical implementation and business understanding.
Before we go deeper, I want you to understand that this is not the “right way” or even a better or even more elegant way to write software. This way, like all the previous generations are tools, tricks and patterns that were designed to help you tackle various levels of complexity. It is not a silver bullet, and if applied in cases where the level of “natural” is low, would end up in creating an impressive amount of artificial complexity.
If you missed it, I have a full article on this topic here:
Now, that you have been warned, “stay a while and listen”…
Architectural Pattern Overview
Structure and Components
The DDD with Aggregates pattern introduces a more domain-centric structure that puts business concepts at the heart of our architecture.
The core components of this architecture revolve around the domain model:
Aggregate roots serve as entry points and consistency guardians for clusters of related domain objects. An Order aggregate root manages OrderItems, ShippingDetails, and PaymentInformation, ensuring they're always modified together in a consistent way. The aggregate root enforces invariants like "order total must match sum of line items" or "shipping address must be valid for selected shipping method."
Entities represent domain objects with identity and lifecycle, distinct from other objects even when their attributes are the same. A Product is an entity because it maintains its identity even when its attributes change—a product with ID 12345 remains the same product regardless of price or description changes.
Value objects capture concepts that are defined by their attributes rather than identity. Money, Address, and DateRange are value objects because two instances with identical attributes are considered the same. They're immutable and often encapsulate validation and domain operations related to their concept.
Domain events represent significant occurrences within the domain that domain experts care about. OrderPlaced, InventoryAllocated, or PaymentProcessed events capture important state transitions that might trigger other processes or be valuable for auditing and historical analysis.
Repositories provide the illusion of an in-memory collection of aggregates while abstracting the details of data storage and retrieval. An OrderRepository lets us work with Order aggregates without concerning ourselves with database tables, query languages, or persistence frameworks.
Command handlers receive commands from the application layer, load the appropriate aggregates through repositories, invoke methods on those aggregates, and persist the resulting state changes. They serve as transaction coordinators but delegate business decisions to the aggregates themselves.
Domain services encapsulate domain operations that don't naturally belong to a single aggregate but represent important business processes. A PricingService might calculate prices based on products, customer segments, and current promotions—a process that spans multiple aggregates.
Responsibilities and Relationships
In the “DDD with Aggregates” architecture, responsibilities are distributed according to domain-driven principles:
Command handlers orchestrate the overall process, including transaction management and persistence. The PlaceOrderCommandHandler loads the necessary aggregates, calls methods on them to perform the business operation, manages the transaction boundary, and ensures the resulting state changes are persisted. While it doesn't make business decisions itself, it is responsible for the overall flow and transactional integrity.
Aggregate roots enforce invariants and coordinate operations across their internal entities and value objects. The Order aggregate ensures that adding a line item updates the order total, checks inventory availability, and maintains the order in a consistent state through all operations.
Entities encapsulate state and behavior related to a specific business concept with identity, think of them like a lesser aggregate. The Product entity manages its own state transitions, enforces its validation rules, and exposes domain-specific operations rather than just providing getters and setters (which is common “anti-pattern”, called anemic domain model).
Value objects encapsulate validation and operations for concepts defined by their attributes. The Money value object handles currency conversions, arithmetic operations, and formatting, ensuring that financial calculations follow business rules consistently. Now, value objects, while not that clear from the start, help you write smaller and easier to understand methods, by giving you the certainty that all parameters are valid, you can focus on the business logic and completely ignore guards and all kind of “null checks” or other “technical” validations.
Repositories abstract data access, providing a collection-like interface for working with aggregates. They handle the complexity of persistence without exposing those details to the domain model, allowing the model to remain focused on business concerns.
Domain services implement operations that span multiple aggregates or don't naturally belong to a single entity. The InventoryAllocationService might coordinate inventory allocation across multiple warehouses based on order details and shipping preferences.
Domain events communicate significant state changes across the system. When an Order is placed, it might raise an OrderPlaced event that triggers inventory allocation, payment processing, or notification services without creating direct dependencies between these components. One thing that should be always in your mind is that domain events should ALWAYS be accepted and processed. They are things that already happened, and there is nothing you can do about this, if you fail to account for this, that the system might end up in an inconsistent state.
Change Frequency Characteristics
With DDD Aggregates, change patterns align more closely with business evolution:
The domain model evolves in response to deepening understanding of the business domain. As we learn more about how orders are processed or how product pricing works, we refine our aggregates to better reflect these insights, creating a virtuous cycle of improving domain alignment.
Business rule changes localize to specific aggregates or domain services. When the rules for calculating shipping costs change, we update the ShippingCalculation value object or ShippingService, without affecting unrelated parts of the system.
Technical concerns like persistence or API formats change independently from the domain model. Changes to database schemas or REST endpoints don't ripple through the domain layer because these concerns are separated by clear abstractions.
Team organization can align with domain boundaries, with teams owning specific bounded contexts or aggregates. The checkout team can evolve the Order aggregate and related components without coordinating with the catalog team that manages the Product aggregate.
Stratification Analysis
Layer Organization
DDD with Aggregates brings a more domain-centric stratification to our architecture, emphasizing the primacy of the domain model.
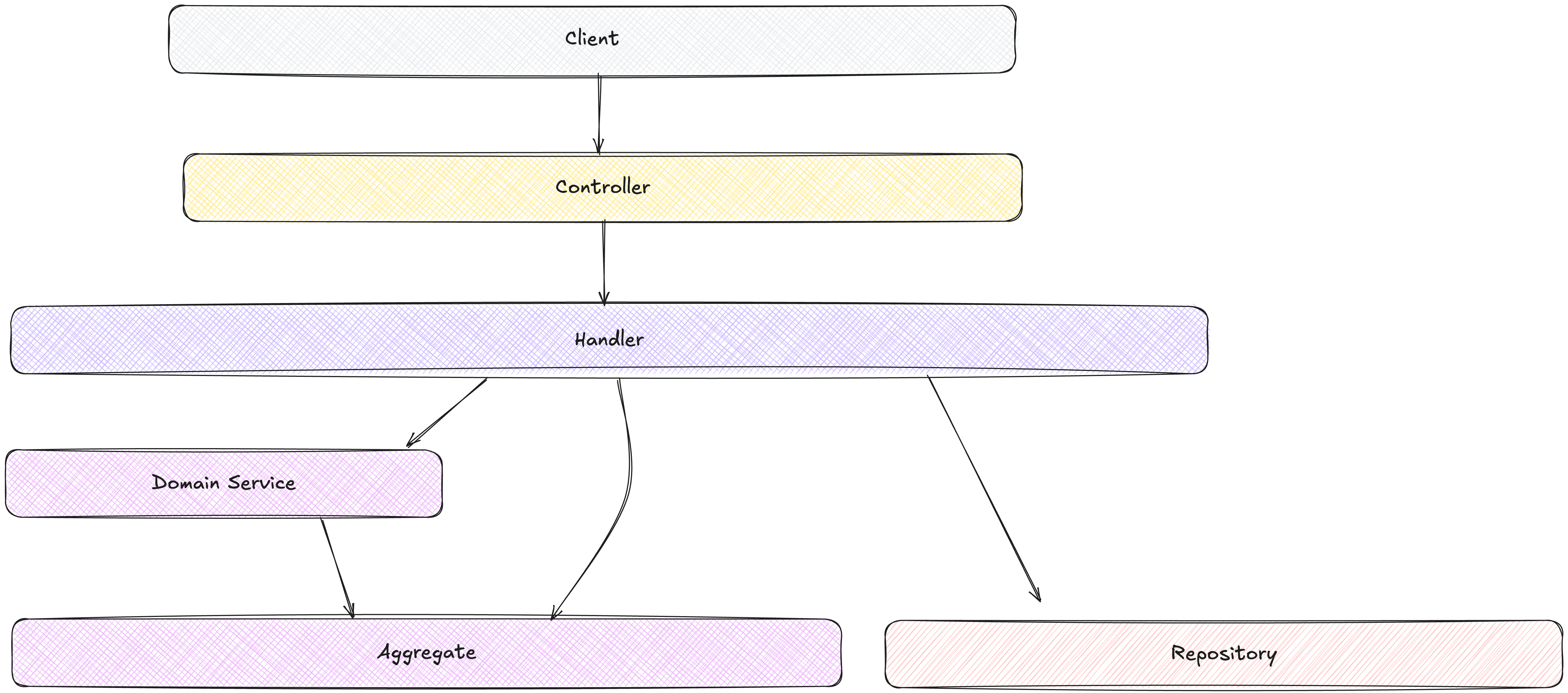
The presentation layer remains responsible for user interaction, translating user actions into commands and queries, and formatting domain data for display. Same as before.
The application layer consists primarily of command and query handlers that coordinate use cases by loading aggregates, invoking their methods, and persisting changes. This layer manages transactions and serves as the bridge between the outside world and the domain model.
The domain layer now takes center stage, containing the rich domain model with aggregates, entities, value objects, and domain services. This layer encapsulates the core business logic and rules in a form that closely mirrors how domain experts think about the business.
The infrastructure layer adapts the abstractions defined by the domain (like repositories) to concrete implementations (like database access code). This layer serves the domain rather than dictating to it, allowing the domain model to remain pure and focused on business concerns.
Dependency Flow
The dependency flow follows the “Dependency Inversion Principle”, with all dependencies pointing inward toward the domain model.
Controllers depend on command and query handlers, which in turn depend on repositories and domain services defined by the domain layer. The domain layer itself has no outward dependencies—it defines interfaces that the infrastructure layer implements.
This inverted dependency structure ensures that the domain model remains isolated from technical concerns, allowing it to focus purely on expressing business concepts and rules. It also creates a system that's more resilient to change, as modifications to persistence or presentation details don't affect the core domain logic.
Within the domain layer itself, dependencies flow from more specific concepts to more general ones. Order entities might depend on Money value objects, but Money doesn't depend on Order. This creates a hierarchy of abstraction that keeps the domain model clean and focused.
Change Isolation
Business rule changes remain contained within specific aggregates or domain services. When the rules for calculating order totals change, we update the Order aggregate without affecting unrelated parts of the system. This makes business evolution more manageable and reduces the risk of unintended consequences.
Technical changes like switching database technologies or updating API formats affect only the infrastructure layer without rippling through the domain model. Since the domain defines abstractions that the infrastructure implements, changes to implementation details don't affect the core business logic.
User interface changes impact only the presentation layer and perhaps some command/query structures, without affecting the domain model. This allows the UI to evolve independently to meet user needs without compromising the integrity of the business logic.
Domain boundaries create natural “expansion points” for system evolution. Different parts of the system can advance at different rates according to business priorities, with changes to one bounded context having minimal impact on others.
Implementation Patterns
Aggregates and Entities
We will not go through this in this article, since languages vary widely in implementing this, and there are a lot of great sources of implementation details.
But to give you a gist of the main ideas.
Aggregates and Entities usually have public getters but private setters, although this might seem “a lot of unnecessary work”, this is what enables you to ensure that the inner state si corect at all times. Also this pushes you to a more explicit and more thoughtful way of designing the model while giving you full control on the behaviour.
There are usually two ways of writing this code, one is the more common “object oriented” way, as described above, but for the more “functional” people you can achieve the same results using a “State Pattern”. Where essentially you hold a private object with the properties ( data ), and only expose methods that can get data or change them. And you can go even further than this in some languages, by having all the methods being pure functions that operate over an immutable state.
The point is that DDD Aggregates are more of a mind set, than an implementation.
Technology-Agnostic Example
Let's examine how DDD Aggregates would handle our e-commerce checkout process:
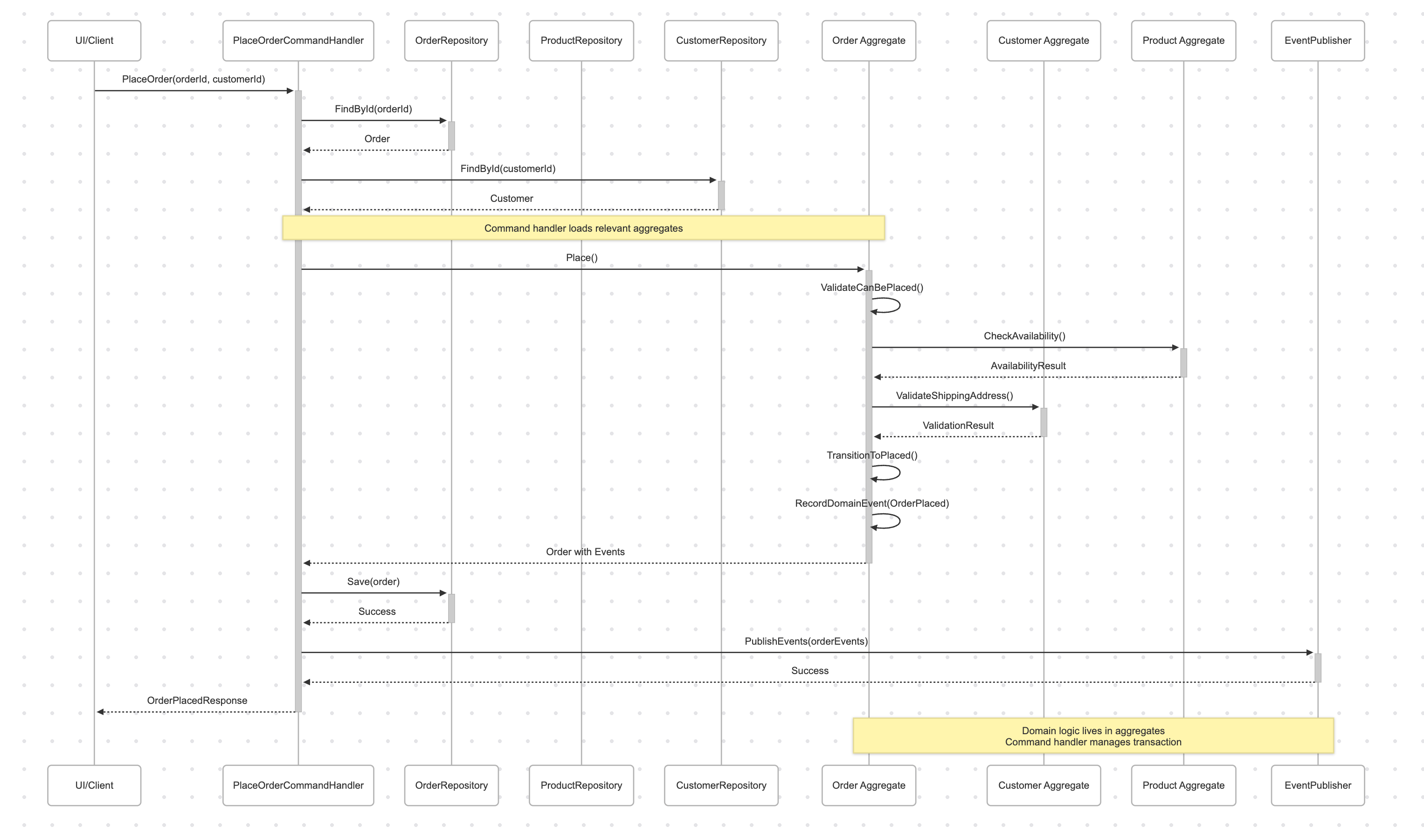
When a customer places an order, the PlaceOrderCommandHandler loads the relevant aggregates (Order, Customer, perhaps Product for inventory checks), then calls domain methods on these aggregates to execute the business operation. The aggregates themselves contain the business logic for validation, state transitions, and calculations.
For example, the Order.place() method might:
Validate that the order is in a state where it can be placed
Check that all line items reference valid products
Ensure the customer information is complete
Transition the order to the "placed" state
Record an OrderPlaced domain event
The command handler coordinates the overall process, manages the transaction boundary, and publishes domain events, but the core business decisions are made by the aggregates themselves.
Now, depending on who you ask, there are multiple camps, some say that aggregates should never call each other, others say they should. Some say always use Domain Services ( another abstraction ), others might prefer an accessor approach ( like a context catching lambda that you pass as a parameter to the aggregate method, so it knows what it is getting back, but not have a direct dependency on the other aggregate).
There is no right way, but what I can tell you from experience, talk to your team, come to an agreement and stick with it until that way of doing things stops to yield the expected results.
Complexity Management
Where Complexity Lives
Aggregates redistribute complexity to align with domain concepts, creating a system that's more intuitive to domain experts even as it grows in sophistication.
Business logic complexity now resides primarily in the domain model—in aggregates, entities, value objects, and domain services. This creates a close alignment between the code structure and the business concepts it represents. When a business expert talks about how orders are processed, we can point to the Order aggregate that encapsulates those rules and behaviors.
Consistency complexity is managed through aggregate boundaries. Each aggregate defines a clear consistency boundary, with the aggregate root ensuring that related entities are always modified together in ways that maintain important invariants. This makes it easier to reason about the system's consistency guarantees.
Behavioral complexity is expressed through methods on domain objects rather than external services operating on passive data structures. Instead of a service that determines if an order can be cancelled, the Order itself has a canBeCancelled() method that encapsulates this business rule where it naturally belongs.
Validation complexity moves from external validators to the domain objects themselves. A ShippingAddress value object knows what makes a valid shipping address, rejecting invalid values at construction time rather than relying on external validation layers.
How the Pattern Distributes Complexity
By redistributing complexity according to domain concepts, DDD with Aggregates creates a system that's more intuitive and maintainable despite its growing sophistication.
Business rules become more discoverable when they're encapsulated in relevant domain objects. When a developer needs to understand how shipping costs are calculated, they can look at the ShippingCalculation value object or the Order.calculateShippingCost() method, rather than searching through service layers or utility classes.
Consistency rules are localized to aggregate boundaries. The Order aggregate ensures that adding or removing line items always keeps the order in a consistent state, with totals reflecting the current items. This localization makes it easier to verify that important business rules are always enforced.
Complexity is stratified by concept rather than technical layer. Instead of having validation logic in one layer, business rules in another, and data access in a third, each domain concept (like Order or Product) encapsulates all the rules and behaviors related to that concept, creating a more intuitive organization.
Domain events distribute the complexity of cross-aggregate coordination. Instead of creating complex dependencies between aggregates, one aggregate can raise events that others respond to, creating a more loosely coupled system that's easier to evolve.
Scaling Characteristics
DDD with Aggregates offers superior scaling characteristics for complex domains:
Conceptual scaling improves as the domain model can evolve to capture increasingly sophisticated business concepts and rules. As our understanding of the business deepens, we can refine our aggregates, entities, and value objects to better reflect this understanding, creating a virtuous cycle of domain alignment.
Team scaling benefits from the clear boundaries between different parts of the domain. Teams can own specific bounded contexts or aggregates, evolving them independently without constant coordination with other teams. The checkout team can refine the Order aggregate while the catalog team evolves the Product aggregate.
Functional scaling is enhanced by the domain-centric organization. New features or business requirements often align with existing domain concepts, making it clear where changes should be made. A new shipping option likely belongs in the Order or Shipping context, while a new product categorization scheme belongs in the Catalog context.
Technical scaling is supported by the separation of domain logic from infrastructure concerns. The domain model can be optimized for expressing business rules, while the infrastructure layer can be optimized for performance, scalability, or other technical considerations.
The Three Dimensions Analysis
Coordination
Coordination in DDD with Aggregates takes a domain-centric approach, with different patterns for coordination within and between aggregates.
Within aggregates, coordination is encapsulated in the aggregate root. The Order aggregate root coordinates the interactions between OrderLineItems, ShippingDetails, and other internal components, ensuring they work together coherently to maintain the aggregate's invariants.
Between aggregates, coordination typically follows a choreography pattern based on domain events. When an Order is placed, it raises an OrderPlaced event that the Inventory context might listen for to allocate inventory, and the Notification context might use to send confirmation emails. This event-based coordination creates looser coupling between different parts of the system.
For operations that span multiple aggregates and require immediate consistency, domain services provide orchestration. An OrderProcessor domain service might coordinate the interaction between Order, Inventory, and Payment aggregates during the checkout process, ensuring that all parts of the operation succeed or fail together.
Command handlers continue to provide transaction coordination, defining the boundaries of atomic operations and ensuring that aggregate state changes are persisted consistently. But they delegate the actual business decisions to the aggregates, keeping the coordination separate from the business logic.
Communication
Communication patterns in DDD with Aggregates differ based on context and requirements.
Within aggregates, communication happens through direct method calls, with the aggregate root controlling access to internal entities and value objects. This encapsulation ensures that the aggregate's invariants are always maintained, regardless of which operations are performed.
Between aggregates, communication typically occurs through domain events, creating a looser coupling that allows aggregates to evolve independently. This asynchronous, event-based communication supports better separation of concerns and can improve system resilience.
For queries, direct repository calls or specialized query services are often used, bypassing the full domain model when it's not needed. This pragmatic approach recognizes that not all operations benefit from the richness of the domain model, especially read-only operations that don't change state.
Command handlers communicate with aggregates through a clear, intention-revealing API defined by the aggregate root. Instead of exposing internal state for modification, aggregates provide methods that express business operations: order.place() rather than order.setStatus(OrderStatus.PLACED).
Consistency
Consistency is managed at multiple levels in DDD with Aggregates, with different consistency models for different contexts.
Within aggregates, strong consistency is maintained by the aggregate root, which ensures that all operations leave the aggregate in a valid state that respects its invariants. This creates clear, well-defined consistency boundaries that align with business concepts.
Between aggregates, eventual consistency is often used, facilitated by domain events. Changes to one aggregate may trigger events that lead to changes in other aggregates, but these changes happen asynchronously, acknowledging that not everything needs to be immediately consistent.
For operations that span multiple aggregates and require immediate consistency, transaction scripts or domain services can provide coordinated updates within a single transaction. But these cases are minimized by thoughtful aggregate design, with boundaries drawn to encapsulate concepts that need to change together.
Consistency rules are expressed explicitly in the domain model rather than being implicit in database constraints or service methods. The Order aggregate's validation methods clearly state what makes an order valid, making these rules more discoverable and maintainable.
Dimensional Friction Points
Aggregates addresses several dimensional friction points that emerge in previous architectural generations.
The tension between encapsulation and query optimization is resolved by separating command and query responsibilities. The rich domain model handles command operations that change state, while optimized query paths can bypass the domain model for read-only operations where the domain behavior isn't needed.
The conflict between aggregate autonomy and cross-aggregate consistency is managed through domain events and carefully designed aggregate boundaries. By drawing aggregate boundaries around concepts that need to change together and using events for looser coordination between aggregates, we can balance autonomy and consistency.
The trade-off between domain purity and technical concerns is addressed through the separation of the domain layer from the infrastructure layer. The domain model can focus on expressing business concepts and rules, while the infrastructure layer handles technical concerns like persistence and messaging.
Testing Strategy
Testing Approach for DDD
DDD with Aggregates enables a more focused and effective testing strategy by clearly separating domain logic from infrastructure concerns.
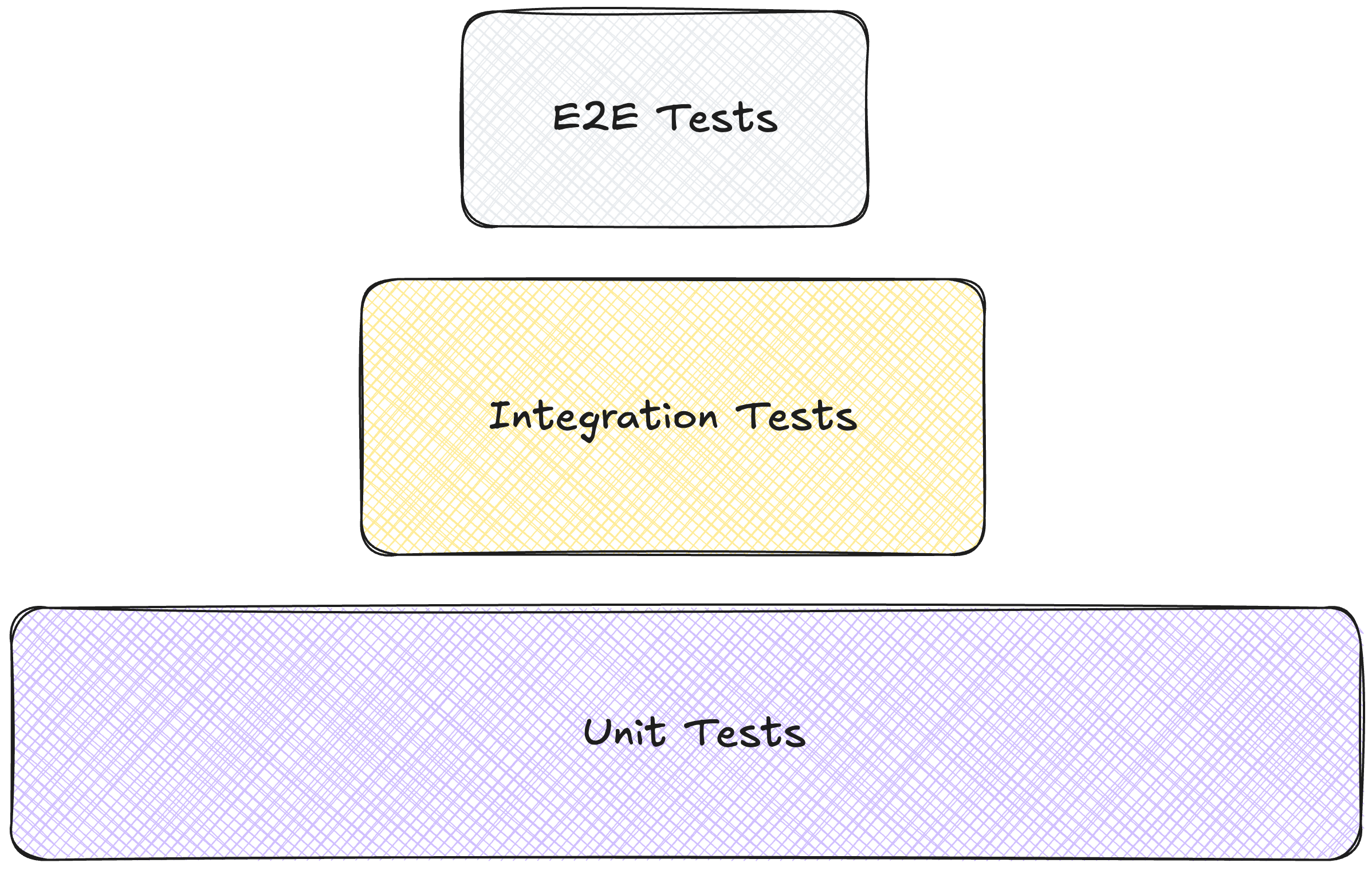
The testing approach for DDD typically follows a classical pyramid:
Many unit tests for domain objects (aggregates, entities, value objects)
Some integration tests for repositories and domain services
Fewer end-to-end tests for critical business workflows
This distribution reflects the concentration of business logic in the domain model, allowing more thorough testing of these critical components in isolation.
The query side remains unchanged from the previous generation.
Test Focus by Layer
Testing focuses on different aspects depending on the layer and type of component.
Aggregates and entities are extensively unit tested to verify business rules, state transitions, and invariant enforcement. Tests ensure that these domain objects correctly implement the core logic of our business, validating that operations like placing an order or updating a product maintain the object in a valid state.
Value objects are tested for correctness of operations and validation rules. Tests verify that these immutable objects correctly implement domain concepts like Money, DateRange, or Address, with appropriate validation and behavior.
Domain services are tested for correct implementation of operations that span multiple aggregates. Tests ensure that these services coordinate the interaction between different domain objects correctly, maintaining the integrity of the overall operation.
Repositories are tested for correct persistence and retrieval of aggregates. Tests verify that these components correctly translate between the domain model and the underlying data store, maintaining the aggregate's state and identity.
Command handlers are tested for correct orchestration of use cases, including transaction management and event publishing. Tests ensure that these components correctly coordinate the application of commands to aggregates and handle the resulting state changes.
Common Testing Challenges
Despite the benefits of DDD for testing, several challenges remain:
Testing aggregate interaction through events can be complex, especially when events trigger asynchronous processes. Tests need to verify not just that the events are raised correctly, but also that they're handled appropriately by their consumers.
Maintaining test data consistency for integration tests requires careful management of aggregate state. Tests that modify aggregate state need to ensure that these changes don't interfere with other tests, either through isolation or careful cleanup.
Testing eventual consistency patterns introduces timing challenges. Tests need to account for the potential delay between when an event is raised and when its effects are visible in other parts of the system.
Verifying business rule implementation requires domain knowledge. Effective testing of domain objects requires a deeper understanding of the business rules they're implementing, making collaboration with domain experts even more important.
When to Evolve
Signs DDD Aggregates Are No Longer Sufficient
As our e-commerce platform continues to grow in scale and complexity, several signs might indicate that DDD Aggregates, while powerful, are reaching their limits for certain parts of our system.
Long-lived processes that span multiple interactions become difficult to track and manage. Order fulfillment might involve multiple steps over days or weeks, with the order passing through various states: picking, packing, shipping, and delivery. Maintaining this state and enforcing the valid transitions becomes challenging within a traditional aggregate.
Complex event flows between aggregates create implicit dependencies that are difficult to understand and maintain. As more and more parts of the system react to events from other parts, the overall behavior becomes less predictable and harder to reason about.
Historical state reconstruction needs emerge, with requirements to understand not just the current state of entities but how they evolved over time. Auditors might need to see not just that an order was cancelled, but all the state transitions and decisions that led to that cancellation.
Performance bottlenecks appear in aggregates that have high contention or complex loading patterns. Popular products might experience concurrency issues during flash sales, or orders with many line items might become slow to load and process.
Reporting and analytics requirements grow beyond what can be efficiently derived from the current state of aggregates. Business analysts might need historical trends, aggregations, and projections that are difficult to generate from the current state of the domain model.
Triggers for Moving to Event Sourcing
Several specific triggers indicate it's time to consider Event Sourcing combined with CQRS as the next evolutionary step:
Audit requirements become more stringent, requiring a complete history of all changes to critical business entities. Regulatory compliance might mandate that we track not just the current state of orders or customer data, but every change made to them over time.
Process management needs exceed what can be modeled with simple aggregate state. Order processing might involve multiple participants, timeouts, compensating actions, and complex state machines that are difficult to represent in traditional aggregates.
Replay and reconstruction scenarios emerge, where the ability to rebuild the state of the system at any point in time becomes valuable. This might be needed for debugging production issues, testing what-if scenarios, or recovering from data corruption.
Concurrency contention on popular aggregates creates performance bottlenecks. High-traffic products or services might experience locking issues with traditional aggregate persistence, limiting system throughput.
Integration with external systems becomes more event-driven, with a need to reliably capture and process events from multiple sources. The system might need to respond to events from warehouse systems, payment processors, or third-party logistics providers.
Transition Strategies
The transition to event sourcing can be evolutionary rather than revolutionary, focusing first on the areas of the system with the most pressing needs.
Start by introducing event capturing within existing aggregates. Instead of just persisting the current state, begin capturing the events that led to state changes, storing them alongside the aggregate. This creates a foundation for event sourcing without immediately changing how aggregates are loaded or processed.
Implement event sourcing for new aggregates or those undergoing significant refactoring. Rather than trying to convert the entire system at once, apply event sourcing to specific aggregates where the benefits are most apparent, such as those with complex audit requirements or process management needs.
Gradually shift from state-based to event-based persistence. As aggregates evolve, move from storing their current state to reconstructing that state from events. This can happen incrementally, with some aggregates using traditional persistence while others are event-sourced.
Develop specialized read models for specific query needs. As query requirements become more diverse and performance-critical, create dedicated read models optimized for specific use cases, gradually implementing the query side of CQRS.
Refine event definitions to capture business intent rather than just state changes. As the system becomes more event-centric, evolve event definitions to express not just what changed but why it changed, capturing the business operations that led to these changes.
NFR Analysis
Non-Functional Requirement Alignment
DDD with Aggregates offers a nuanced alignment with non-functional requirements, with particular strengths in maintainability and domain alignment:
Maintainability: ⭐⭐⭐⭐⭐ (Excellent alignment with business concepts makes the system more intuitive to maintain)
Testability: ⭐⭐⭐⭐⭐ (Domain logic is isolated and encapsulated, facilitating thorough testing)
Scalability: ⭐⭐⭐⭐ (Aggregate boundaries create natural seams for system distribution)
Performance: ⭐⭐⭐ (Some overhead from rich domain model, but can be optimized where needed)
Extensibility: ⭐⭐⭐⭐⭐ (Domain-centric organization makes it clear where new features belong)
Reliability: ⭐⭐⭐⭐ (Explicit business rules and invariants improve system correctness)
Strengths and Weaknesses
Aggregates bring significant strengths to our architecture:
Domain alignment creates systems that more closely reflect how business experts think about the domain. When our code structure mirrors business concepts and rules, it becomes more intuitive for both developers and domain experts, improving communication and reducing translation errors.
Business rule encapsulation ensures that rules are enforced consistently wherever they apply. By encapsulating validation and behavior in domain objects rather than spreading them across services or controllers, we ensure that important business invariants are always maintained.
Clear boundaries between different parts of the domain make it easier to understand, modify, and extend the system. Aggregate boundaries and bounded contexts create natural seams for system evolution, allowing different parts to change at different rates without affecting the whole.
Improved testability comes from the isolation of business logic in domain objects. With business rules encapsulated in aggregates, entities, and value objects, we can test these rules thoroughly in isolation, without requiring complex setup or infrastructure.
However, DDD also introduces challenges:
Learning curve and conceptual complexity can be steep for teams accustomed to simpler architectural styles. The rich vocabulary of DDD—aggregates, entities, value objects, bounded contexts—requires time and effort to master, potentially slowing initial development.
Performance overhead from the rich domain model can impact system responsiveness. The additional layers of abstraction and the focus on business concepts rather than technical optimization can sometimes lead to performance challenges that require careful design.
Repository abstraction can hide important performance characteristics of the underlying data store. By hiding the details of data access behind repository interfaces, we might miss opportunities for database-specific optimizations or encounter unexpected performance bottlenecks.
Aggregate design challenges emerge when determining the right boundaries. Drawing aggregate boundaries too narrowly can lead to excessive coordination between aggregates, while drawing them too broadly can create large, unwieldy aggregates that are difficult to work with.
Optimization Opportunities
Even within the DDD pattern, several optimizations can enhance performance, scalability, and maintainability:
Aggregate size optimization balances consistency needs with performance considerations. By carefully drawing aggregate boundaries to include only those entities that genuinely need to be modified together, we can create smaller, more focused aggregates that are easier to load, modify, and persist.
Lazy loading of aggregate components can improve performance for large aggregates. Not all parts of an aggregate need to be loaded for every operation, and lazy loading can defer loading less-frequently-needed components until they're actually accessed.
Caching strategies at various levels can improve performance for read-heavy operations. From caching individual aggregates to caching query results, strategic caching can significantly improve system responsiveness without compromising the domain model's integrity.
Optimistic concurrency control can improve throughput for aggregates with moderate contention. Instead of locking aggregates during modification, optimistic concurrency allows multiple operations to proceed simultaneously, detecting and handling conflicts only when they actually occur.
Architect's Alert 🚨
DDD Aggregates bring tremendous power for modeling complex domains, but they can easily become bloated and unwieldy if not carefully designed. Watch for aggregates that grow too large, encompassing too many entities or responsibilities. These "God Aggregates" often indicate a misunderstanding of the domain or a failure to identify natural consistency boundaries.
Be particularly vigilant about aggregate references. Aggregates should reference other aggregates by identity (ID) rather than holding direct references to them. Direct references between aggregates create implicit dependencies and can lead to stampedes where loading one aggregate cascades into loading many others.
Consider the transaction boundaries carefully when designing aggregates. An important principle of DDD is that a single transaction should modify only one aggregate, preserving their autonomy and minimizing contention. If you find that many of your operations need to modify multiple aggregates in a single transaction, it might indicate that your aggregate boundaries need refinement.
Remember that DDD works best when:
The domain has significant complexity that justifies the investment
Domain experts are available and engaged in the modeling process
The team is willing to invest in learning and applying DDD concepts
The business value comes from handling complex rules and workflows correctly
DDD might be overkill for:
Simple CRUD applications with minimal business rules
Technical infrastructure with little domain logic
Systems where performance is the primary concern
Projects with short timelines and limited complexity
Conclusion and Next Steps
DDD with Aggregates represents a significant evolution in our architectural journey, acknowledging that as our domain grows in complexity, our code structure should directly reflect business concepts and rules. By encapsulating both state and behavior in domain objects, we create a system that's more closely aligned with how domain experts think about the business.
Our e-commerce platform now models orders, products, customers, and other key concepts as rich domain objects with behavior rather than just data structures. The Order aggregate enforces important business rules like "an order can only be cancelled if it hasn't shipped," ensuring these rules are consistently applied throughout the system. Product pricing and inventory management are encapsulated within the Product aggregate, creating a clear home for these important business capabilities.
However, as our platform continues to evolve, we notice increasing requirements for auditing, historical analysis, and complex process management. Customers want to see the complete history of their orders, business analysts need historical trends, and operations teams need to manage complex fulfillment workflows that span days or weeks.
These emerging needs point toward the next evolution in our architecture: Event Sourcing. This approach would build on the domain model we've established with DDD, but store the history of events rather than just the current state, enabling richer historical analysis, better audit capabilities, and more sophisticated process management.
The journey from State Aggregates to Event Sourced Aggregates represents more than just a technical evolution. It reflects a deeper understanding of our domain and its temporal aspects—recognizing that capturing the history of state changes is as important as modeling the current state, and that this history itself has business value.
Questions for Reflection
Consider your own systems through the lens of DDD Aggregates:
Where in your domain would rich business objects with both state and behavior create the most value? Complex business processes like order management, subscription handling, or financial transactions often benefit most immediately from the DDD approach.
How clear are your current aggregate boundaries, and do they align with true consistency needs? Well-designed aggregates are cohesive units that model concepts that need to change together, creating natural consistency boundaries.
What business rules or invariants in your domain deserve explicit modeling? These might be validation rules, state transition constraints, or calculation logic that's currently spread across services or controllers.
How might domain events improve the loose coupling between different parts of your system? Events representing significant state changes can enable better separation of concerns while maintaining system integrity.